自從 2015 年開始聽 Podcast 至今也約 5 年了。最近發現我聽 Podcast 的時間和訂閱節目的數量都很多,有點資訊超載的感覺,尤其新節目越來越多(大部分是台灣的),排擠到原本訂閱的節目,跳過了好多單集。
以下是我一直以來的猜想:
- 我訂閱的節目在最近兩三個月變得很多,但是真正去聽的很少,所以有些該退訂。
- 我聽節目的喜好程度是中國普通話節目 > 台灣國語節目 > 台語節目 > 英語 >> 日語。
- 一開始都是聽中國的節目,而從某一段期間開始狂聽英語節目。
- 開始在家工作之後似乎聽的時間變多了,儘管沒有通勤。
於是我好奇我的行為有沒有什麼改變。
尤其是「訂了沒在聽」的問題,一直困擾著我。我有公開一個我訂閱中的節目列表。目前是大約 100 檔節目。但是我不可能全部都聽完。
但是數據去哪裏找呢?
我用的 Podcast App 叫做 Castro,裡面有個打星 (Star) 的功能。這個計畫本來是想要做打星列表,公開出來。但是 App 裡面沒有匯出的功能,備份檔裡面雖然有節目和單集的歷史紀錄,但只有內部索引號碼 (UUID),讀不到節目名稱。去信開發者也只收到罐頭回信。
本來很氣餒,但後來找到有人透過祕技把資料庫匯出,寄送到自己的 Email 信箱。基本上他做的是把事件灌到另一個紀錄個人嗜好的 App 裡面。
有了原始資料庫就可以做很多事情了,包括收聽行為的分析。拿到了資料庫之後,就用 SQL 和 Google 試算表做簡單的數據分析。剛好遇到日本的黃金週,旅遊計畫也因為武漢肺炎 (COVID-19) 疫情而被取消了,所以我有完整的長假可以玩這些資料。(技術細節請見文末)
以下是一些 Insights。直方圖的數據是根據收聽時間 × 節目主要語言來彙整的,以一週為單位,橫軸是收聽的週(以週日為開始),越往右邊越靠近現在(2020 年 5 月)。
數據最終更新的時間是五月初,所以五月的數據不完整。以及我開始用 Castro 大約是 2018 年 11 月,所以先前的數據是空白的。不過一年半的數據也夠分析了。
總播放單集數
首先最直覺的問題是「我到底都聽了多少單集」。
跟其他 Podcast App 不同,Castro 的基本設計是一個播放清單和收件匣 (Inbox)。Castro 把訂閱 Podcast 節目類比成訂閱電子報,有新內容的時候先進入收件匣,要聽的時候再移入播放清單,且可以自由調整播放順序。我在 Castro 中設定大部分的節目是進入 Inbox,只有少數每日更新,或是乾貨特別多的節目,可以直接進入播放清單。如果你是播客主,Castro 客戶端的下載 +1 就是發生在此刻。
如果用 SEO 的術語來說,就是「閱覽數」(PV)。除了我有信心可以每集必聽的節目之外,還有標題內文吸引我所以點了下載的單集。聽說 SEO 界還有所謂的 clickbait 伎倆——以聳動或嘩眾取寵的標題騙人家點進來看,增加 PV 及增加廣告曝光次數。幸好 Podcast 仍然還在主動訂閱的模式,clickbait 比較難奏效。
以下這張圖就是我自己的 PV 數。
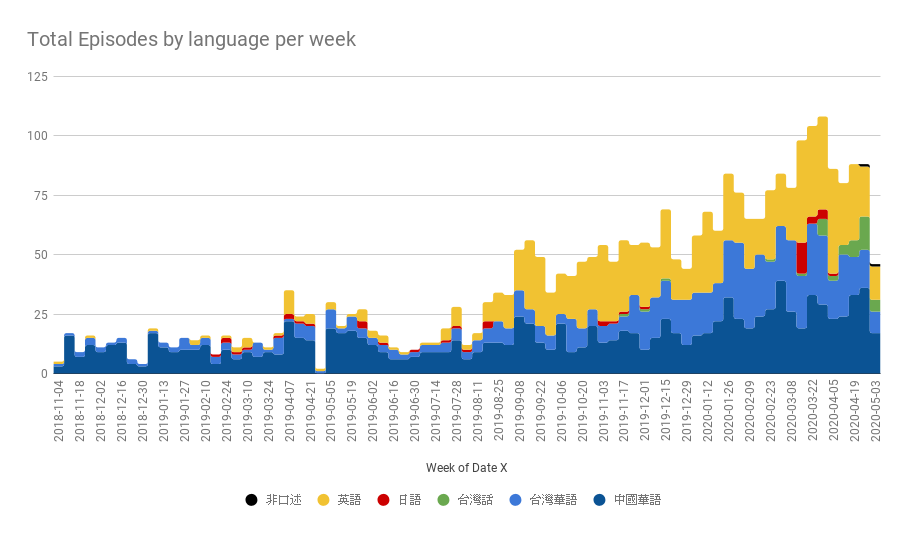
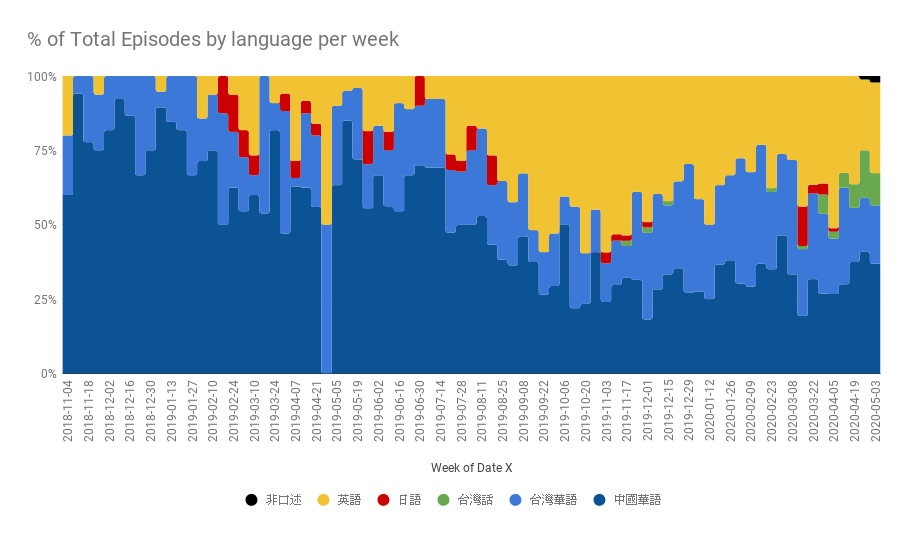
- 雖然華語佔了超過一半,但是英語的佔比也不少。現在大致上中國、台灣跟英語的節目很平均。
- 很明顯有個趨勢是收聽的英語單集越來越多,甚至一度超越華語節目。但如今大概還是保持在 30~40%。
- 我訂閱了好幾檔每日出新番的 NPR 英語節目,如 Coronavirus Daily、The Indicator from Planet Money、Short Wave等,所以這也讓英語(黃色區塊)變得比較大片。另外比較積極更新的還有 Vox 的 Reset、中國的故事 FM等。
- 2020 年 3 月間,一週播放到 100 個單集似乎是有點太超過了。這段期間是我大量試聽不同的新節目。
- 2019 年底開始,台灣的華語節目大爆發。可能是為了試聽所以點了許多單集,但是現在佔比又被中國華語吃回來了,這可能跟我自己喜好的節目風格有關。
- 只要我去外地出遊就幾乎不聽,如 2019 年日本黃金週連假、新年連假。
- 2019 年 9 月開始聽節目的時間突然變得很多,這是因為我把 PlayStation 4 賣掉了。
總播放時長
上述的播放單集並沒有回答一個問題:我播放了那麼多的單集,加起來到底都花了多少時間在聽 Podcast?
透過統計資料庫裡面的「播放進度」就可以算出每週大約播放了多少小時的節目。當然因為它只有進度(秒),所以它是原始音訊檔的時間長度,忽略快轉跳過的時間、加速播放、自動移除空白而省下的時間,也忽略了重複播放多次的加總時間(只計算最後一次播放到哪裏)。但因為我的習慣通常是不會重複聽第二次,所以不精確的部分不太影響這個指標。
那麼來看圖說故事。縱軸是加總的播放進度,單位是小時:
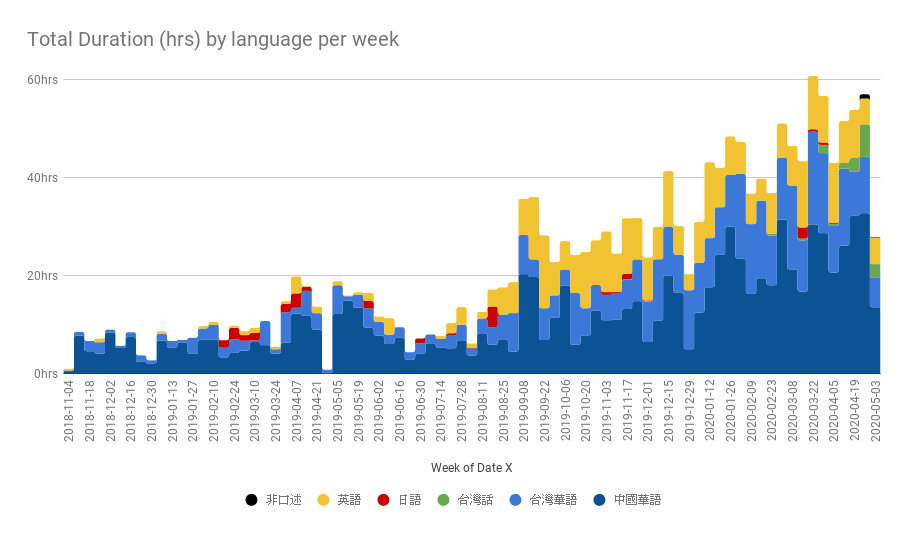
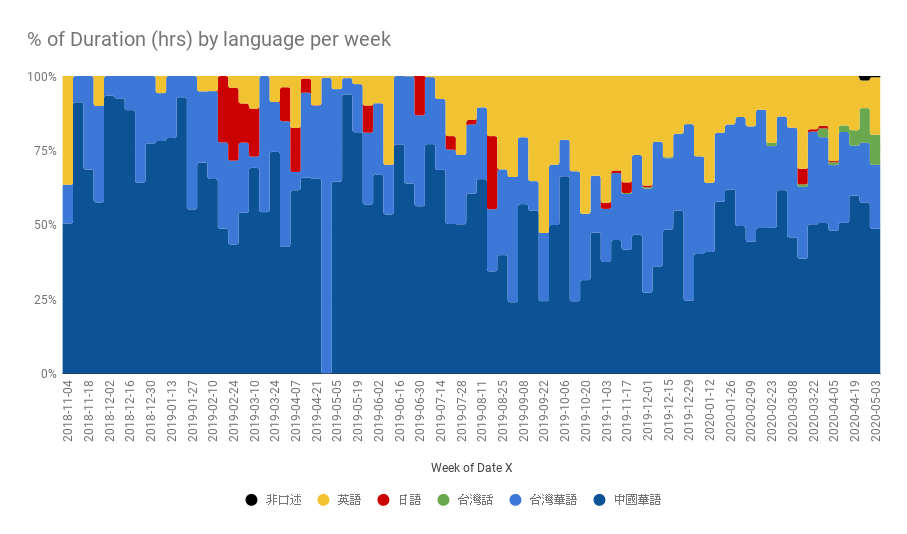
- 儘管之前的單集統計說明我聽的節目是中國華語、台灣華語、英語平均,但從總播放時長來看,還是中國華語居多,可能我收聽的中國節目大部分都很長。
- 2020 年 2 月中開始,因應武漢肺炎疫情,公司要求我們在家上班。從那之後我聽節目的總時長一度下跌,但是後來又漲回來了。我猜測是跟我沒有通勤有關,所以花了一些時間建立新習慣。
- 2020 年 3 月中曾經一度達到一週 60 小時,相當於平均一天超過 8 小時。原本我以為我程式寫錯,去看了原始資料還真的都有印象。可能是一邊開著一邊工作,當白噪音,其實也沒在認真聽。這種節目就是我該退訂的。
- 2019 年中以前聽的內容大部分都是中國的節目
- 儘管台灣的節目變多了,進入我耳朵的聲音大部分還是中國的節目
- 從 2019 年 7 月開始重拾英語收聽習慣,但最近有被台灣節目排擠的趨勢
- 2020 年 4 月開始聽了一些台語節目,基本上都是從中央廣播電台的閩南語頻道來的
- 日語節目我曾經多次嘗試,多次放棄
追新番指數
上述的收聽及紀錄不考慮新番舊番,也就是說如果我在 2020 年 5 月選了 2018 年發布的單集收聽,還是算在 2020 年 5 月。如果要解答訂閱的即時收聽量,也就是「新番一定聽」和「訂了沒在聽」的指標,則要考慮發布日期和收聽日期。
下圖計算的方式是每週有給一個節目按「播放」就算 1 次,按多次也只算 1 次。並且只計算發布後 7 天內收聽的節目,所以可以排除去聽老集數的誤差(播客主所謂的「長尾」)。
於是就可以看出每週真正去追的新番數量:
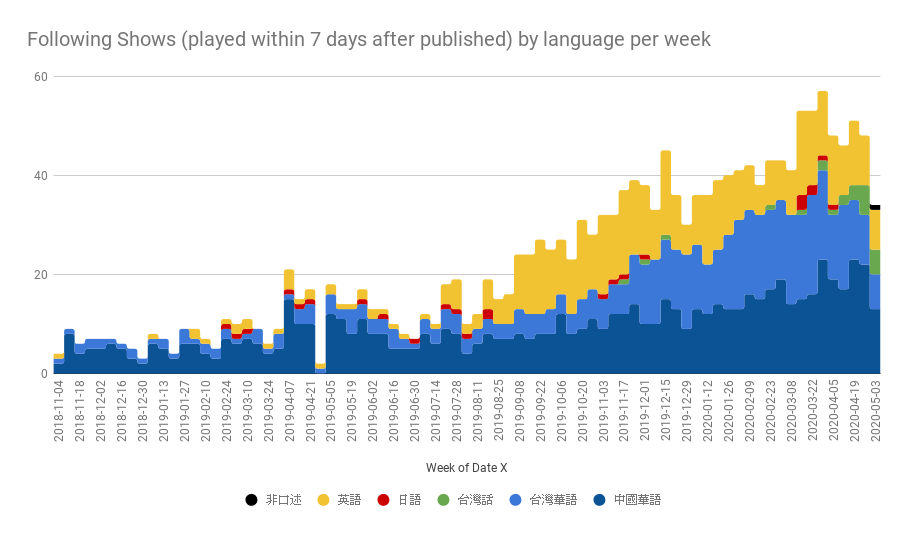
- 儘管台灣節目大爆發時期我訂了許多台灣節目,但是隨後也退訂了不少,反而新訂了一些中國的節目。再度強調,這還是跟我個人收聽的口味有關。
- 真正大量追番的時期要從 2019 年 9 月算(賣掉了 PlayStation 4);在此之前大概都在每週 10 檔節目左右。也是在幾乎同一時期去追了不少英語節目。
- 目前(2020 年 4 月)是維持在每週追 40~50 檔節目。將來應該會變少。
- 我所謂「訂了 100 檔節目」真正有持續在追的也只有一半。事實上可能有很大一部分已經停更了,不是我主動跳過的。
忠誠指數
上面的追新番圖表是照語言區分的。我事實上最好奇的是「我需要退訂哪些節目」。
做播客主的人一定會好奇:你的節目真的有人在聽嗎?儘管託管網站後台看得到下載數量,但你卻不知道他們有沒有播放(除非是 Apple Podcasts、Spotify 等平台有第一手數據)。甚至你也不知道這其中有多少是訂了之後沒在聽。
接下來這項統計,就是我對節目的忠誠度。這個數據是如此計算的:
對於每一檔節目,找到最初我播放的單集。從那之後發布的每一單集,根據月份加總時間長度。然後和我實際收聽的長度相除。
這樣就能得到一個「消化率」:雖然有訂閱,而且它在這個月有發新番,但有多少 % 是我真正去聽了。
這就能看出我對節目的忠誠度,以及看看那些我可以退訂,反正我也沒在聽。
再一次用 SEO 的術語來解釋,前文的單集總數如果是 PV 的話,忠誠指數就是「逗留網站時間」。吸睛的標題可能會吸引我打開網頁,但真正有內容的長文會讓讀者流連忘返,標題卻不見得吸睛。
然而對於 Podcast 來說,花時間製播的內容還是得要有人聽完才有意義。標題和節目筆記只是一種廣告,轉化發生在節目的消化。但這樣的轉化除非是發布端到收聽端整合的大平台(Apple Podcast, Spotify)才能精確計算,不像 YouTube 有製播-回放-統計一條龍的鏈,用 RSS 發布的 Podcast,天生就很難一個平台通吃,一般的泛用型 Podcast App 因為單純是下載檔案,後端只能看到下載數據,無法向播客主回報收聽紀錄等資訊。所以這種數據對播客主來說是夢寐以求的。
以下這張截圖只是一張試算表的一部分。因為 5 月的內容還算新,所以我還沒聽完。但是如果我往下捲,就會發現許多紅色、有發新番但根本沒在聽的節目。截圖中的節目基本上都是我還有固定在追的。
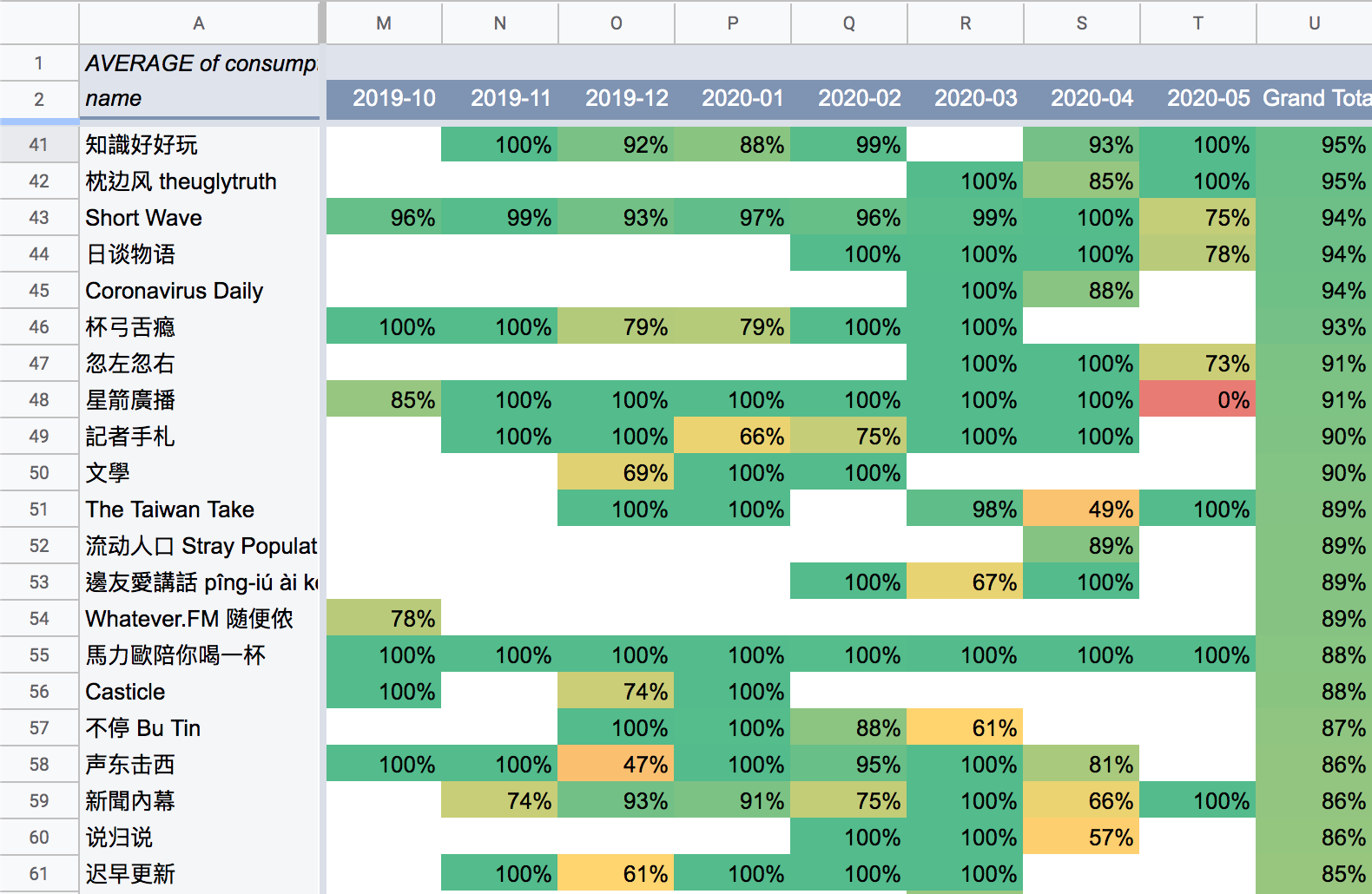
當然,因為有語言的標籤,所以可以照語言分類:
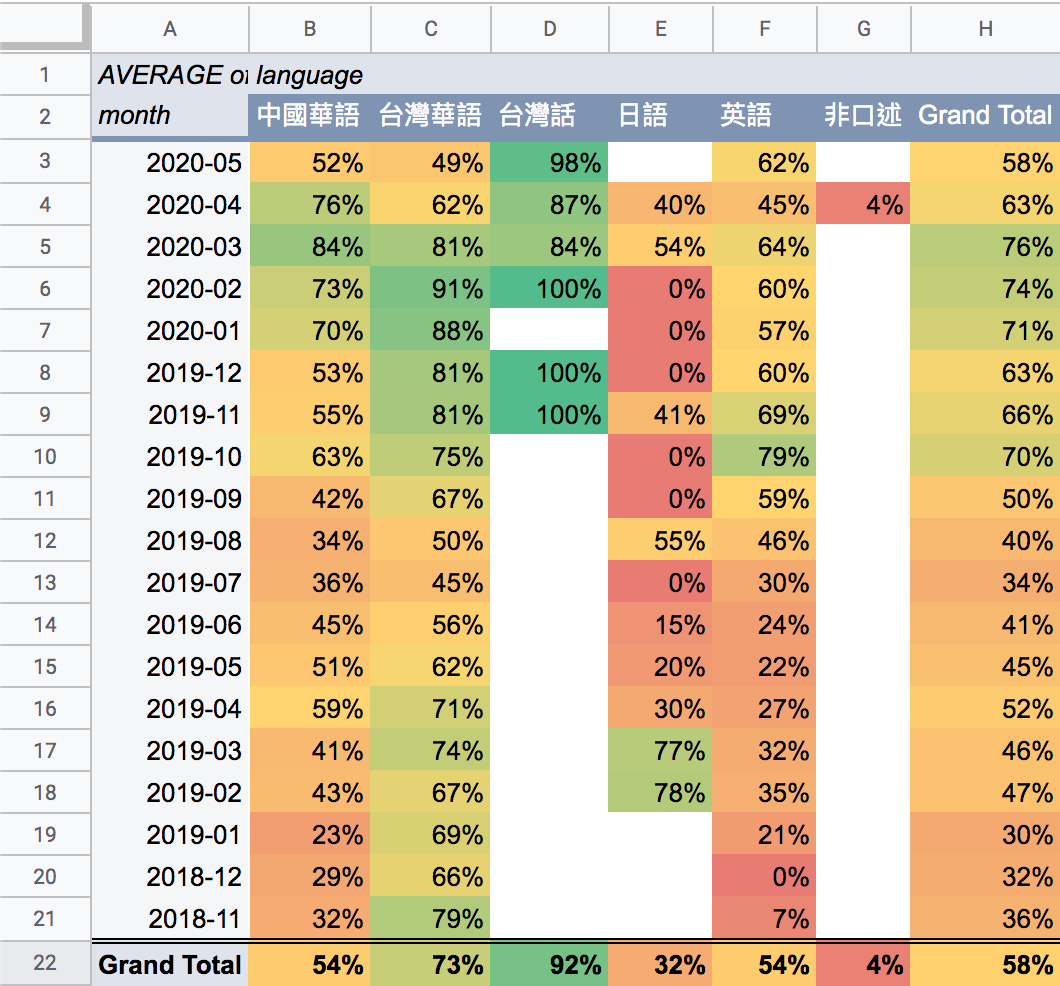
我的積極目標是要讓最新月份的數據盡量在 70% 以上,或是偏綠色,這表示我有訂的都有在聽,盡量降低出一集就 Skip 一集的壓力感。
後記:用數據洞察自己的沈迷
運用大數據平台分析個人的「小數據」也不是第一次了。在 2019 年 11 月也做過類似的事情,那時候是分析 Twitter 發文紀錄。資料量也不是很多,才三萬多條 ,不過已經可以看到一些有趣的趨勢。
今天做這個 Podcast 分析,雖然最初的目標是拉出資料庫來發布我的打星播放清單,但是當我手上拿到一個充滿事件紀錄的資料庫的時候,我就轉而運用我在工作學到的知識來分析數據,以及把流程給自動化。
從 2019 年末開始我有觀察到,每週推出的單集,多過我可以消化的量,但當時不以為然,只覺得 Castro 可以幫我統整單集,我自己決定如何收聽,已經比 Overcast、Pocket Cast 等基於播放列表的 App 來得方便了。但最近看到 Inbox 有 40 個單集,我就感到問題的嚴重性。儘管在家工作的時間變多了,但同時我也開始覺得「聽不完」,那麼 Podcast 作為娛樂工具就失去了它的意義,不如說是一種沈迷。
以前我也有類似的感覺。2012 年以前我沈迷 PTT。2016 年以前我沈迷日本動漫,每季都會追新番,看不完。2019 年以前會玩 PS4 的暢銷大作。2019 年中以前會一直逛 Facebook。如今是 Podcasts。
雖稱沈迷,這種沈迷卻不是因為樂在其中,而是來自怕落伍的壓力 (Fear of Missed Out, FOMO)。我只是一味地輸入而沒有咀嚼之後再輸出,為的只是保持自己的資訊跟「大眾」同步。如果讀新聞是為了因應瞬息萬變的世界(瘟疫下更重要),那麼追逐娛樂的新事物,雖然可以消化時間,有時還能改變自己的思考模式,但如果沒有輸出,並無法給自己帶來好處,只是徒增壓力。
我依稀記得 Cal Newport 在《Digital Minimalism》一書中闡述一種觀念,就是我們要去尋找對自己最有效用的科技,而非單純別人也在用所以你也用。狂刷 Netflix、社群網站等行為,都不是最有效用的利用法。作者建議讀者去尋找對自己最有效用的科技,並對於任何新科技都保持嚴格檢驗的態度,「我是否確實體會到他對我生活帶來的美好」、「我榨取了它對我最有價值的部分了嗎」而非不假思索地接受新科技。
用台灣人最愛說的 CP 值(性價比,Cost-Performance Rate)來解釋的話,成本(代價)是你花了多少時間在這些娛樂,但最重要的性能(效能)卻是可以自己定義的。它可以是消遣無聊的生活、創作而得到的爽、對世界發表意見的輸出。但如果成效不彰,可能你用的方法不適合你,也可能該工具本來的設計就不是讓你爽,而是讓你看廣告,所以吸引你的注意力。但最重要的是,定義一個效能 P,然後檢視你付出的代價 C 跟實際獲得的 P 有沒有夠高,藉此來檢驗科技是否給自己帶來好的效果。
話說回我自己。如前所述,我放棄了不少興趣,動漫、電動、SNS。近來我跟 Netflix、電子書處於一種我很滿意的平衡,我也找到了我和 Facebook 新的平衡。但眼看 Podcast 好像快要吃垮我自己,現在做這種數據研究,給自己一些未來的指引,可能還不遲。
附錄:技術細節 for Geeks
分析的方式:
- Google Spreadsheet 樞紐分析表 (TIL 這根本上古神器)
- 原本還用了
=QUERY()但發現我要的結果直接用樞紐分析表即可
- 原本還用了
- Amazon Athena 寫一些 View Query 倒 CSV 出來
- 目前是手動取代成 TSV 然後貼到 Google 試算表,因為還要 workaround 節目標題裡面有逗號的情形
- 最終可以從 API Gateway 從 S3 直接出 CSV 檔案,用
=IMPORTCSV()直接匯入 Google 試算表 - 最終還可以掛入 Step Functions 來自動下 query 更新 CSV 檔案
- 學到了
PARTITION OVER可以得到類似樞紐分析的結果
資料彙整的方式:
- 用一支程式跑在 Lambda 抽出 SQLite 資料到 JSON,每個 Query 上限 1000 條,避免一次拉太多導致 Lambda memory bloat;盡量用小規格機器跑。
- Schema 寫在 AWS Glue Table 裡面,手動寫,沒有用 Glue Crawler。
- 手寫一來是因為可以直接抄 SQLite 的 schema,二來是原始資料庫有一些欄位可以手動 cast,例如時間戳記原本是
integer,可以 cast 成timestamp。 - Glue Crawler 爬一次要兩分鐘,也是錢。
- 手寫一來是因為可以直接抄 SQLite 的 schema,二來是原始資料庫有一些欄位可以手動 cast,例如時間戳記原本是
- 語言的標籤是我在 AirTable 手動加,然後複製貼上到 Google 試算表的。根據的是節目主要語言,而非單集語言。所以如果一個台灣的華語節目突然有一集在講英語,那算在台灣華語。由於出現的次數很低,不影響整體結果,所以不予區別。
下載資料庫檔案的方式:
- 祕技是在 Castro > Settings > Support 那邊長按 Email Support,就可以選擇 Email with Database and Logs。因為我的資料庫有36MB,所以只能用 iCloud Mail Drop 寄送。
- 用 Zapier Email Parser 抓出 iCloud Mail Drop 的下載地址
- 讓 Zapier 執行一段 JavaScript 打到一個 API Gateway 執行 Step Functions
- API Gateway 可以發 API Key 比較方便
- Step Functions 不需要讓 client 等 Lambda 結果,直接回 execution ID
- Zapier JavaScript Task 的 timeout 是 1 秒
- Step Functions 的內容:
- 第一個 Lambda 開 Puppeteer 尋找 iCloud Mail Drop 附件的下載地址;規格比較高
- 第二個 Lambda 直接用 axios 讀 stream 丟到 S3
- 因為 Puppeteer 的 Chromium 要下載檔案比較麻煩,無法確定檔案何時下載完成,必須一直 poll 下載資料夾,直到沒有
*.crdownload為止。 - 最後一步是啟動另一個 Step Functions 把 S3 裡面的資料庫檔案變成 JSON(如上述資料彙整)。分開是為了讓第二個 state machine 不要跟下載綁在一起,這樣要抽資料就可以直接從 S3 讀現成的資料庫。
一些淚:
- 嘗試用 AWS SAM 寫 Node.js 程式,一開始蠻順利,到後來發現
sqlite3有系統依賴,在 macOS 上面sam build的話會編譯成 macOS 用的 binary,無法跑在 Lambda 的 Linux 上面。必須用sam build -u跑在 Docker 裡面編譯才行。但是非常慢。- 既然拿得到下載網址,也許可以直接寫一個 Docker image 跑在 Fargate 然後直接
wget+sqlite3 | jq+aws s3 sync就好了。
- 既然拿得到下載網址,也許可以直接寫一個 Docker image 跑在 Fargate 然後直接
- 要寄送 Castro Support Email,iOS 必須有 Mail App。其他第三方 App 不行。
- 因為要從 iCloud 下載檔案,以及連結 Zapier,服務都開在美區似乎網路延遲比較低。
- CloudFormation deploy API Gateway 似乎不會 deploy stage。
一些懸念:
- 不知道 Castro 什麼時候會把這個輸出資料庫的功能下架。
- 結果我還沒做打星播放列表。