最近 Twitter 又提醒了我的週年慶。2008 年我註冊 Twitter 帳號,前前後後在 BBS, Plurk, Facebook 之間輾轉來去,現在只剩下 Twitter 和 Instagram 是還有持續在使用的社交網路。
最近受到《Digital Minimalism》觀念的影響,理解到過度使用社交網路會影響身心健康及工作效率,於是有意識地拒用社交網路(希望有機會寫一篇文章談談拒用的歷程)。不過因為被 Twitter 提醒週年慶,也開始好奇,11 年來我用 Twitter 的習慣有什麼改變。
結果就是花了半天的時間做出這張圖表:
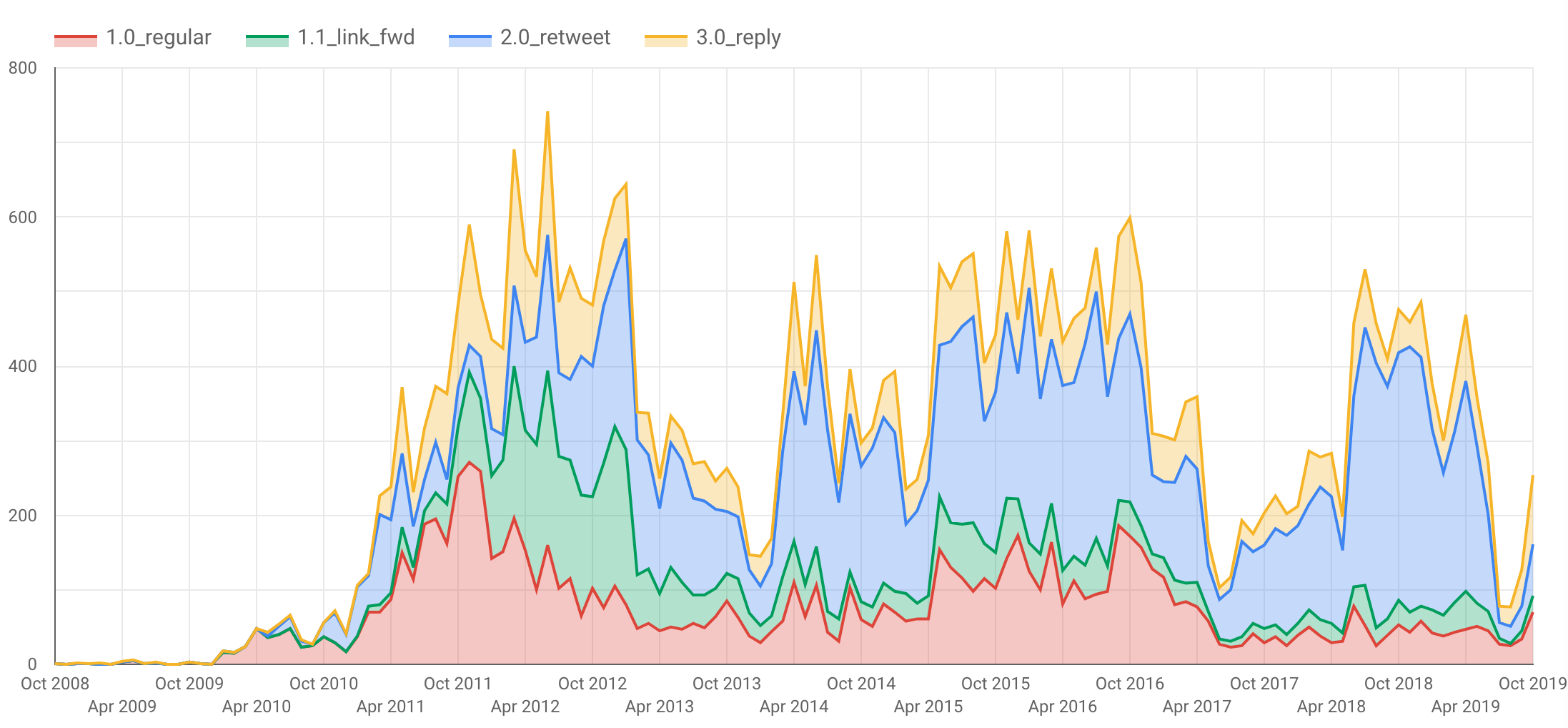
Series 的定義如下:
1.0_regular單純發文1.1_link_fwd轉貼連結2.0_retweet單純轉發別人的推文3.0_reply在 Thread 中回覆別人
其中有幾個明顯的低谷,主因是農曆過年我不太上網。
而 2017 年中起我發文的量變得很低,主因是我換到一個做得很開心的工作,牢騷變少了,自然發文也就變少了。這也反映了我一直都把 Twitter 當牢騷垃圾桶的心態。
最後是 2019 年約 7 月起急劇降低,這是我開始實踐 Digital Minimalism 的時期。不過上個月(10 月)好像快破功了。
一些高峰值我不願意去深究,我猜可能是年輕氣盛跟人家在網上吵架吧。
接著就來講講我是如何做出這張圖表的。
取得 Twitter 的資料
要做分析,首先要有資料。一開始想說是不是要寫機器人去爬 API,但事實上 Twitter 提供個人數據下載服務,在 Your Twitter Data 頁面可以索取下載。這服務應該是來自一些國家政府的要求,Facebook 也提供一樣的功能。
Twitter 稱下載回來的資料是 JSON 格式,但實際上卻是封裝在 JavaScript 程式碼裡面。聽不懂?舉個例子:
這是 verified.js 的內容:
window.YTD.verified.part0 = [ {
"verified" : {
"accountId" : "9999999999",
"verified" : false
}
} ]
這是我期待的 JSON:
[ {
"verified" : {
"accountId" : "9999999999",
"verified" : false
}
} ]
每個檔案都是長這樣。眼尖的 JavaScript 工程師應該看得出來,前面多了 window.YTD.xxx.part0,你得丟進 JavaScript Runtime 把檔案都 evaluate 一遍才能得到資料,還得事先初始化 window.YTD.xxx object,而且是存在記憶體裡面。
而像我這種每天發牢騷的 Twitter 用戶,至今累積 3.7 萬條推文,下載回來的數據就相當可觀。我的 tweet.js 高達 48 MB。整包丟進 Runtime 再寫程式分析是很不切實際的事情。
不過好在這些檔案除了開頭是一個 assignment 之外就都是 JSON 了,全都是 primitive types,statement 最後面也沒有分號(😉),所以直接取代開頭也就行了:
sed 's/^window.YTD.tweet.part0 = //g' < tweet.js > tweet.json
灌到資料庫裡
為了高效率搜尋和分析,我需要把資料灌到資料庫裡面。當然我有好幾個選項:我可以開一個 ElasticSearch 直接灌進去,也可以刻 Schema 灌到 PostgreSQL 裡面,甚至把所有 JSON structure 都打平丟進 Excel 也可以。
不過以上幾個方法都比不起找一個雲端大數據分析服務來得簡單,雖然很像用牛刀殺雞。我一開始選擇了 Google Cloud 的 BigQuery,而且發現它很符合我當下的需求,所以就沒有研究別的方案了。
首先要灌資料。在 Console 開一個 Data Set 很簡單。灌資料就有點問題了。你可以從本機上傳,但是上限是 10MB。我有 48MB 的 JSON 要傳,只能透過 Google Cloud Storage。然而它又有一個限制:JSON 必須是 newline delimited 的。
這是一般的 JSON Array:
[
{
"a": 1
},
{
"a": 2
},
{
"a": 3
}
]
這是所謂的 newline delimited:
{"a": 1}
{"a": 2}
{"a": 3}
沒錯,就是一行一個 object,用換行符號 \n 切開。
要把上述的 tweet.json 轉換成 newline delimited 格式,只要用 jq 即可:
jq -c '.[]' > tweet.gbq.json < tweet.json
現在你可以上傳檔案到 Cloud Storage 並匯入資料了。
欸,那 Schema 呢?免煩惱,只要打開自動偵測即可!
Auto detect
☑️ Schema and input parameters
分析資料
GCP 的 BigQuery 是可以用 SQL 分析的。大致上跟一般的 RDBMS 一樣,只有 function 之類的不太一樣。以下是我是用的 SQL。
首先是做一個 view 來拉出我分析要用的 metadata。用 Query editor 玩玩看,然後按 Save view 即可:
SELECT
id,
parse_datetime("%a %b %d %X +0000 %Y", created_at) as timestamp,
starts_with(full_text, "RT @") as is_retweet,
in_reply_to_user_id IS NOT NULL as is_reply_thread,
ARRAY_LENGTH(entities.urls) <> 0 as has_links,
full_text --- 肉眼參考用,實際分析不會用到
FROM `<table>` --- 這裡取代成你的 project.dataset.table
長得像這樣:
id |
timestamp |
is_retweet |
is_reply_thread |
has_links |
full_text |
|---|---|---|---|---|---|
99999999 |
2018-03-02T12:34:56 |
true |
false |
true |
RT @jack: ... |
幾個注意的點:
created_at匯入是 String type,原文如Wed Mar 02 12:34:56 +0000 2018,時區固定在 UTC。BigQuery 不會幫你自動轉換成時間,所以自己 parse。- 所有的轉推,包括官方轉推,都是
RT @開頭。但是entities.urls裡面會包含原推的超連結。所以is_retweet和has_links會同時true。
畫圖
View 弄好之後就可以對它下 Query,例如:
select
timestamp,
if(is_retweet, "2.0_retweet",
if(is_reply_thread, "3.0_reply",
if(has_links, "1.1_link_fwd", "1.0_regular")
)
) as tweet_type
FROM `<view>`
order by id asc
上文提到 is_retweet 和 has_links 可以同時 true,為了畫圖方便起見,我用了一個有點複雜的 if() 來決定哪個優先。
Query 下好之後你應該會發現有個按鈕叫做 “Explore with Data Studio“。這就是我拿來畫圖的工具。你可以把 Data Studio 想像成 Excel 的圖表工具,只是它的資料源是 Google Cloud Platform 的某個 source。
為了方便肉眼閱讀,我設定了這些:
- Dimension: Year Month (Show as: YYYYMM)
- Break Down Dimension: tweet_type
- Break Down Dimension Sort: tweet_type, Ascending(這也是我加了 1.0 等數字的原因)
Data Studio 提供了許多圖表可以用,像題圖的 Stack Area:
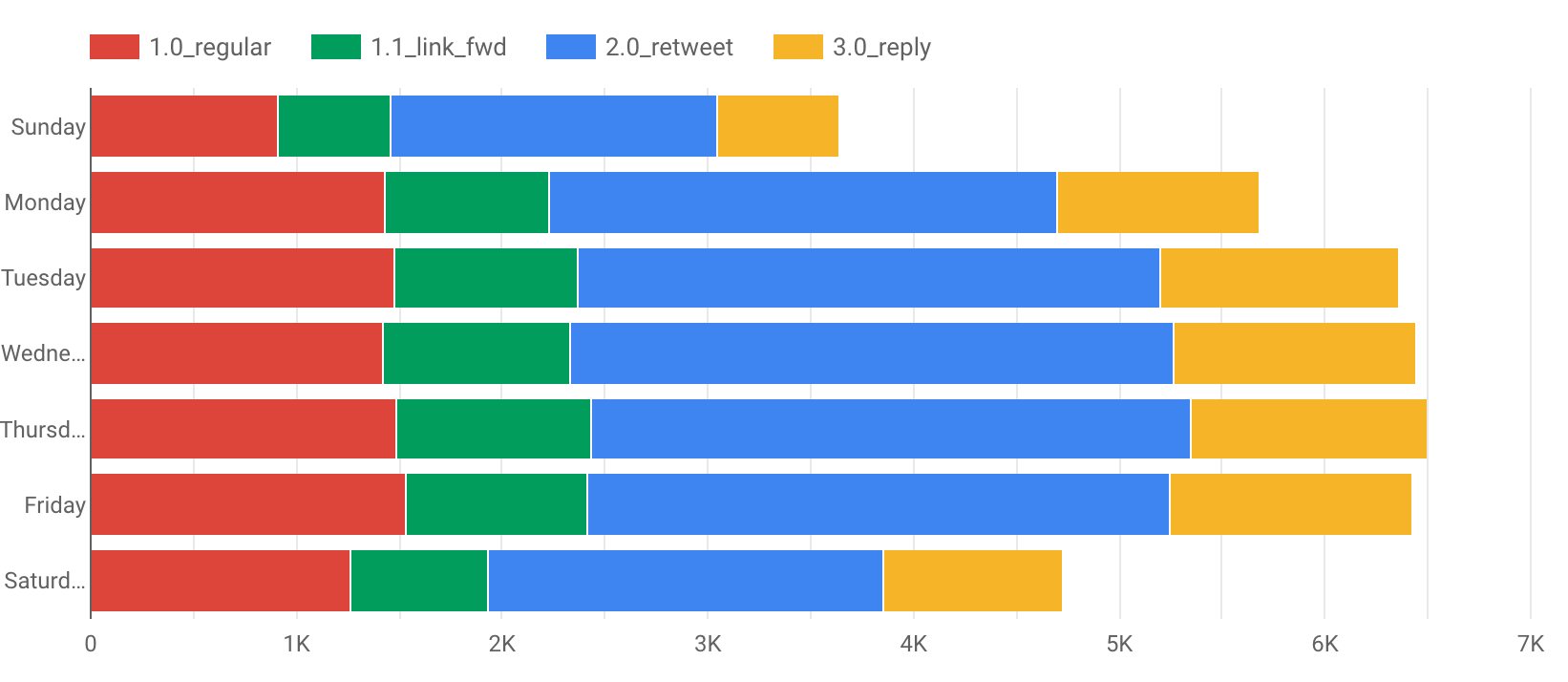
或是Stacked Bar, 可以看出我沒有 Monday Blue 但有 Thursday Blue :(Dimension Format 設成 Day of Week )
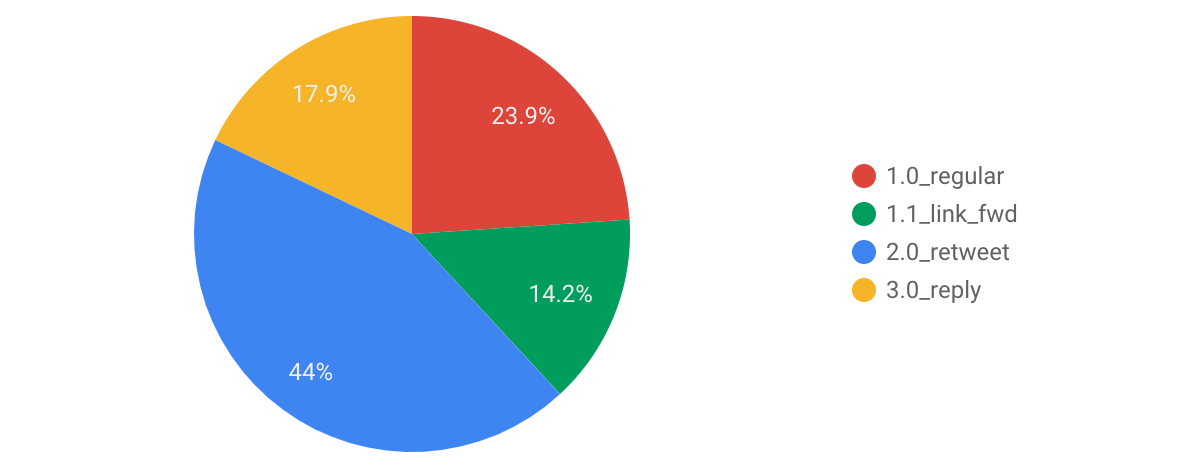
或是 Pie Chart,證明了我真的是轉貼魔人,近 60% 是轉推和分享連結:
結論:數據要分析才有意義
現在的工作上會碰到一些 SRE(System Reliability Engineering)的挑戰,需要設事件、做 log pipeline,在大量的雜訊裡找到系統有問題的訊號。我不是負責 SRE,但我需要負責送 event 出去,好讓他們可以分析。如果套到 Twitter 歷史資料來看的話,每一個近況更新(推文)都是一個事件,metadata 自然是有意義的,但拉長遠來看,我也可以得知自己上網習慣的變化。附帶一提,如果透過自然語言分析去處理內文,也可以建立自己想法的模型跟情緒,這也就是為什麼劍橋分析事件中,他們可以針對某特定族群下假訊息的廣告,也是為什麼你應該小心那些臉書小遊戲和算命 app。
雖然這裡展示的工具是 GCP BigQuery + Data Studio,但實際上應該有很多工具可以做到同樣的事情。身為 Web 工程師,SQL 對我來說沒什麼困難,但人工匯入資料建立 schema 是我不太想花時間做的事情,這也是我選擇 BigQuery 的原因:它可以自動偵測 schema。
可惜當初刪除 Plurk 的時候沒有下載備份,現在要分析也沒辦法了。就當作過往雲煙吧。