Apple File System, or APFS, has been a hot topic since last year. Mac users and developers are eagerly looking forward to its final release. And in fact, APFS also solves a problem that we have now on HFS+: the exchangeability problem of file names with the Accented Latin (like é as in café), and Japanese Kana.
Accented Latin and Kana File Names Finally Work as Expected in APFS
To try these out, you can download a sample code from chitsaou/apfs-docker-unicode-poc.
Consider you have the following files in your Docker project:
$ cat café.txt
I like Moonbucks Coffee!
$ cat ありがとう.txt
ありがとう means Thank You!
And a simple Dockerfile:
FROM alpine:latest
COPY . /
Put these files under an HFS+ disk. Build the image and run it:
$ docker build -t test-image .
$ docker run test-image cat café.txt
cat: can't open 'café.txt': No such file or directory
$ docker run test-image cat ありがとう.txt
cat: can't open 'ありがとう.txt': No such file or directory
The file will not be accessible if you type its name with the keyboard in your terminal or source code. (To type é, press Opt-E then e)
However, if you build the image from an APFS disk, it will work. First, create an APFS image and mount it:
$ hdiutil mount foo.sparseimage -mountpoint /Volumes/apfs-image
$ cd /Volumes/apfs-imagehdiutil create -fs APFS -size 1GB foo.sparseimage
Copy the files above into it, and try again:
/Volumes/apfs-image $ docker build -t test-image .
/Volumes/apfs-image $ docker run test-image cat café.txt
I like Moonbucks Coffee!
/Volumes/apfs-image $ docker run test-image cat ありがとう.txt
ありがとう means Thank You!
It works! ✨
So if you have to handle file names with accented Latin characters, or even Japanese characters in Docker, you can simply wait until the APFS’s final release, or convert to ascii-only representation like cafe or Romaji. You can also avoid HFS+ by building the images on a Linux-based CI server, instead of macOS.
The rest of this post will briefly describe the reason why it doesn’t work on HFS+, with some Unicode knowledges.
Problem of File Name with Combined Chars in HFS+
Say that we have a file named café.txt, and we know each char’s Unicode code point as well as it’s UTF-8 code (note that é char is a two-byte C3 A9 in UTF-8; read this if you want to know why):
Unicode UTF-8
c U+0063 0x63
a U+0061 0x61
f U+0066 0x66
é U+00E9 0xC3A9
. U+002E 0x2E
t U+0074 0x74
x U+0078 0x78
t U+0074 0x74
Now let’s see how it’s represented in HFS+:
$ touch café.txt
$ ls *.txt | od -t x1 -c
0000000 63 61 66 65 cc 81 2e 74 78 74 0a
c a f e ́ ** . t x t \n
We can see that the 4th byte is 0x65 (e) followed by 0xCC 0x81. What exactly is this CC 81? If we reverse it from UTF-8 we’ll find that it’s [U+0301](http://www.fileformat.info/info/unicode/char/0301/index.htm) Combining Acute Accent.
On the other hand, in Docker AUFS:
$ docker run -it alpine sh
# touch café.txt
# ls *.txt | od -t x1 -c
0000000 c a f 303 251 . t x t \n
63 61 66 c3 a9 2e 74 78 74 0a
This time we get a C3 A9 code sequence, which matches the UTF-8 code of é char.
And if we try it in APFS:
/Volumes/apfs-image $ touch café.txt
/Volumes/apfs-image $ ls *.txt | od -t x1 -c
0000000 63 61 66 c3 a9 2e 74 78 74 0a
c a f é ** . t x t \n
This time we also get a C3 A9 sequence, the same as that in a Docker AUFS disk.
So why is there such difference?
Unicode NFD: How HFS+ Represents é and が
As shown above, the representation of é in HFS+ is 65 CC 81 rather than UTF-8’s C3 A9 . This form is called Unicode Normal Form Canonical Decomposition, or NFD, while the C3 A9 form is called Normal Form Canonical Composition, or NFC. With NFD, é will be represented as e followed by ◌́ (U+0301).
You can read more on Wikipedia’s “Unicode equivalence” article.
In HFS+, a file name will be encoded in Unicode NFD form. It seems that when Docker builds an image, the file names are copied as-is. So if we have a file named with characters that were converted to NFD on HFS+, and copy it to Docker, it will not be accessible via the most commonly used NFC form.
But it will work if the file is copied from an APFS disk. Since APFS does not convert file names into NFD, the file names are the same as what we have typed into the terminal or source code.
How does Apple File System handle filenames?
APFS has case-sensitive and case-insensitive variants. The case-insensitive variant of APFS is normalization-preserving, but not normalization-sensitive. The case-sensitive variant of APFS is both normalization-preserving and normalization-sensitive. Filenames in APFS are encoded in UTF-8 and aren’t normalized.
HFS+, by comparison, is not normalization-preserving. Filenames in HFS+ are normalized according to Unicode 3.2 Normalization Form D, excluding substituting characters in the ranges
_U+2000_–_U+2FFF_,_U+F900_–_U+FAFF_, and_U+2F800_–_U+2FAFF_.Source: Apple File System FAQ
Voiced Kana (Daku-on)
In fact, this NFD conversion also happens in Japanese.
There are 2 kinds of scripts in Japanese: Kana (仮名) and Kanji (漢字). Kana, with around 100 characters, are mostly used for the Japan-origin phrases like ありがとう (thank you), or loan words like ハンバーガー (hamburger), while Kanji is a set of characters shared with the East-Asian culture sphere.
Some Kana chars have two sounds: 清音 (sei-on, means voiceless) and 濁音 (daku-on, means voiced). For example, コ /ko/ is sei-on, and ゴ /go/ is daku-on. The way daku-on is represented in Japanese is by adding a double-dotted dakuten mark at the right-top corner of a sei-on Kana. Such contract is similar to the unvoiced and voiceless contrast in English, for example “coat” /kot/ vs “goat” /got/, where /k/ sound is unvoiced, and /g/ sound is voiced.
In most cases, sei-on and daku-on are individual characters in Unicode, for example, コ is U+30B3, and ゴ is U+30B4. However, it can also be represented in NFD form, so ゴ becomes コ followed by ◌゙ (U+3099 Combining Katakana-Hiragana Voiced Sound Mark). Now let’s go back to our original issue…
Voiced Kana Representation in HFS+
Say we have a file named ありがとう.txt . The third character が is the one with voiced sound mark. Their Unicode representations are as follows (Mind that chars other than .txt are all encoded as 3-byte sequences in UTF-8, so you can find it later in the byte sequence):
Unicode UTF-8
あ U+3042 0xE38182
り U+308A 0xE3828A
が U+304C 0xE3818C
と U+3068 0xE381A8
う U+3046 0xE38186
. U+002E 0x2E
t U+0074 0x74
x U+0078 0x78
t U+0074 0x74
Now let’s inspect it in HFS+: (try this in sh rather than bash)
$ touch ありがとう.txt
$ ls *.txt | od -t x1 -c
0000000 e3 81 82 e3 82 8a e3 81 8b e3 82 99 e3 81 a8 e3
あ ** ** り ** ** か ** ** ゙ ** ** と ** ** う
0000020 81 86 2e 74 78 74 0a
** ** . t x t \n
You can see が is encoded as E3 81 8B E3 82 99 , while E3 81 8B is U+304C か, and E3 82 99 is U+3099 ◌゙ , the voice mark.
Let’s try again in Docker AUFS:
$ docker run -it alpine sh
# touch ありがとう.txt
# ls *.txt | od -t x1 -c
0000000 343 201 202 343 202 212 343 201 214 343 201 250 343 201 206 .
e3 81 82 e3 82 8a e3 81 8c e3 81 a8 e3 81 86 2e
0000020 t x t \n
74 78 74 0a
This time we get a E3 81 8C code sequence, which matches the UTF-8 code of が character.
And if we try it in APFS:
/Volumes/apfs-image $ touch ありがとう.txt
/Volumes/apfs-image $ ls *.txt | od -t x1 -c
0000000 e3 81 82 e3 82 8a e3 81 8c e3 81 a8 e3 81 86 2e
あ ** ** り ** ** が ** ** と ** ** う ** ** .
0000020 74 78 74 0a
t x t \n
0000024
The same E3 81 8C sequence as in Docker AUFS.
Again, if we build a Docker image and copy the file from a HFS+ disk, it won’t be accessible, because when you type ありがとう it is usually in NFC form, not NFD. But if we do so from an APFS disk instead, it will work.
That is, the accented Latin problem happens during Docker build, will also happen in the Japanese file names.
Alternative Solution: convmv
There is another solution that you can use: converting file names from NFD to NFC during build process, but adding such workaround just for macOS (development machine) spends too much effort with no much return, and makes it harder to maintain. In my case, I eventually renamed all Japanese file names to ASCII-only names (Romaji, romanization of Japanese). After all, Japanese people are familiar with Romaji.
You can take https://gist.github.com/JamesChevalier/8448512 as an example. But as far as I tried, it doesn’t work well for the Japanese Kana.
One More Thing: Atom Git Status
I’ve been using Atom for more than 1 year. There was an issue annoyed me for some time, but has been resolved during my research of the Unicode file name thing.
Suppose you have a Git repository, and there is a file named café.txt .
In Atom’s tree view, it is always displayed as new (green), even if git status is clean.
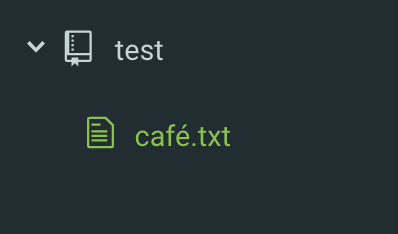
But if the repository exists in an APFS disk, it won’t be displayed as new after checked into the repository.
Conclusion
Understanding how texts are encoded in the computer system is always fun. I remember that when I was young, I learned that BIG-5 (encoding system used by Traditional Chinese) is double-byte, and there is a famous 許功蓋 (Hsu-Kong-Kai) problem, in which these characters uses \ as the second byte, causing a string to be recognized as escape character like \“ and crash a compiler or a database system. When I was studying in the college, I learned how UTF-8 encodes Unicode efficiently while keeping the compatibility with ASCII. They must be very smart to come up with such idea.
I studied this problem by Google and try-n-error, found no good explanation so I wrote this. If you found anything wrong or you’d like to add more, please point out in the comments!